
The slides for this video are shown below:
Slide 1

Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is module 5: “Introduction to the Format Phase.”
Slide 2

This module provides you with an overview of the Format phase. By the end of this training, you should be able to:
- Describe the Format phase
- Determine when the Format phase should be employed
- Specify the view and JCL parameters necessary to use it
- Verify the results of Format phase processing
Slide 3

The Format phase is the final possible phase of the Performance Engine processes. Views that require only extraction and no aggregation are completed at the Extract phase. Any view that requires aggregation or summarization must continue to the Format phase.
Slide 4

The Format phase is required to:
- Summarize records
- Use output record filtering which is applied after records are subtotaled
- Produce sorted outputs
- Create delimited files, and
- Make hardcopy formatted printed reports
Slide 5
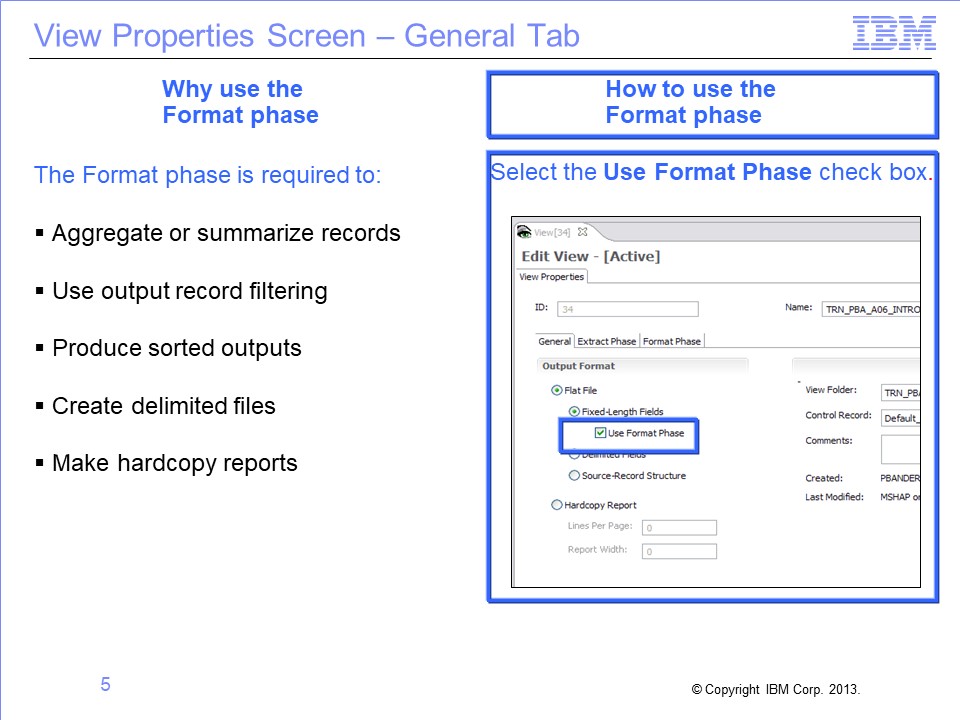
The Format phase is run for views by selecting the Use Format Phase check box on the View Properties screen. Views that require the Format phase can be run at the same time as views that end at the Extract phase (“extract only views”).
Slide 6
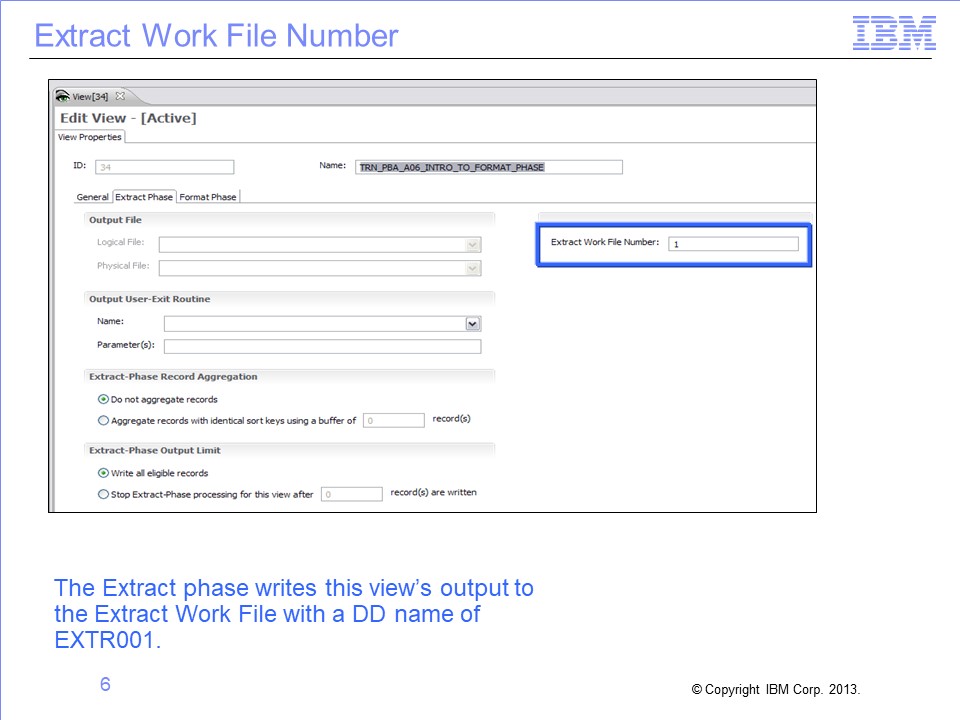
The “Extract Work File Number” identifies temporary file which receives output for this view from the Extract phase and is further processed by the Format phase. The output DD Name used in the Extract phase is a concatenation of letters “EXTR” with three digits representing the Extract Work File Number, beginning with zeros if necessary. For example, the Extract phase outputs for this view would be written to an Extract Work File with a DD name of EXTR001.
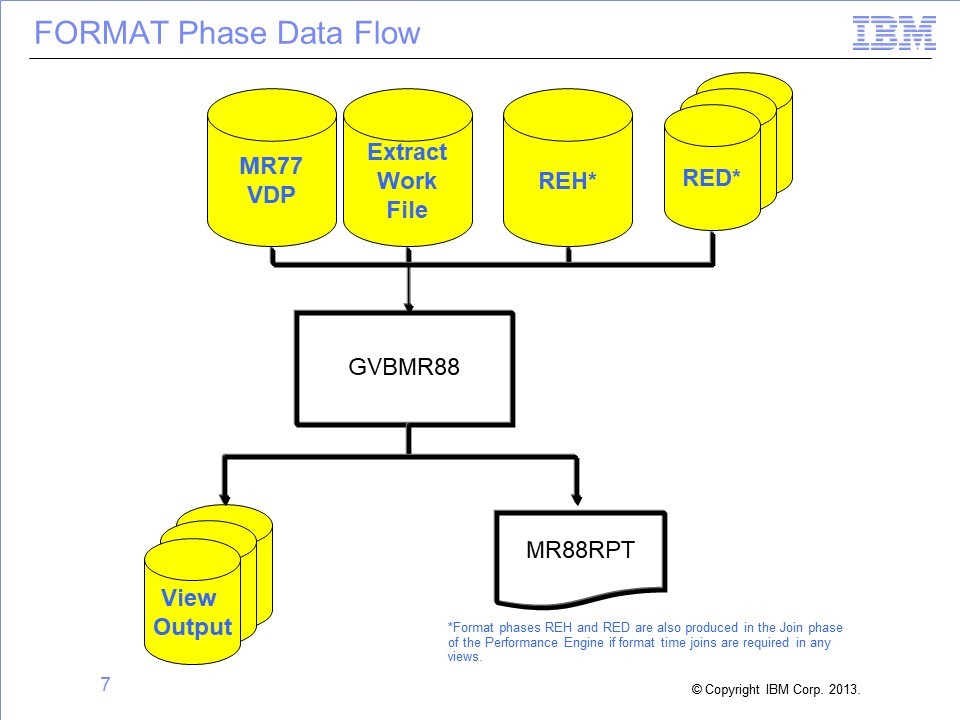
Slide 7
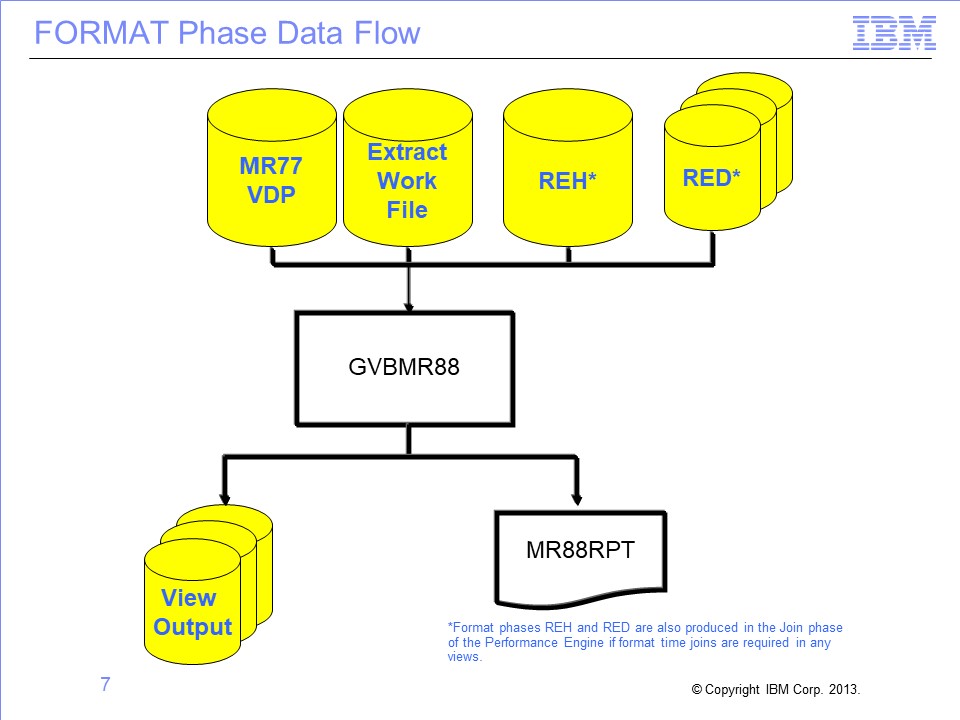
The primary SAFR program in the Format phase is GVBMR88. MR88 reads the MR77 VDP, REH, and RED files created by earlier steps, along with the assigned Extract Work file. It then sorts, summarizes, and formats the data, producing one or more View Output files.
Slide 8
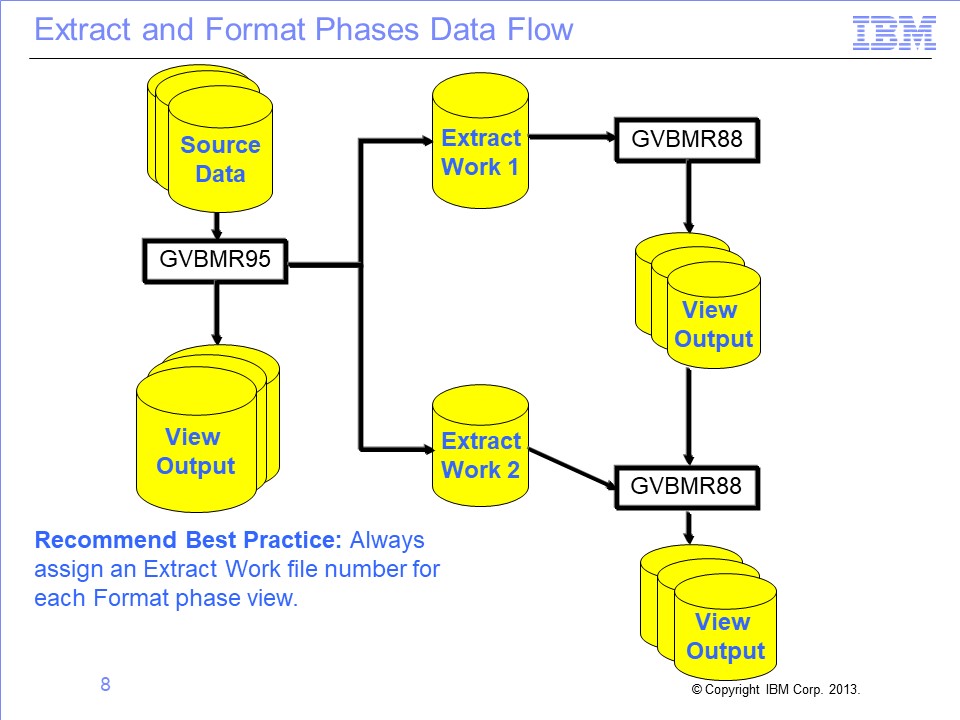
Multiple Format phase processes can be run simultaneously, each processing one or more aggregation views. The Extract Work files have a special internal SAFR format. The total number of Extract Work files is set in the Extract phase as the STDEXTR=nnn parameter, where nnn is the file count.
Views with no Extract Work file number specifically assigned are given a default value in the Performance Engine execution. The assignment can change depending upon the mix of views being run, which may be different between test and production applications. Therefore, it is always best to assign an Extract Work file number to a view.
Slide 9
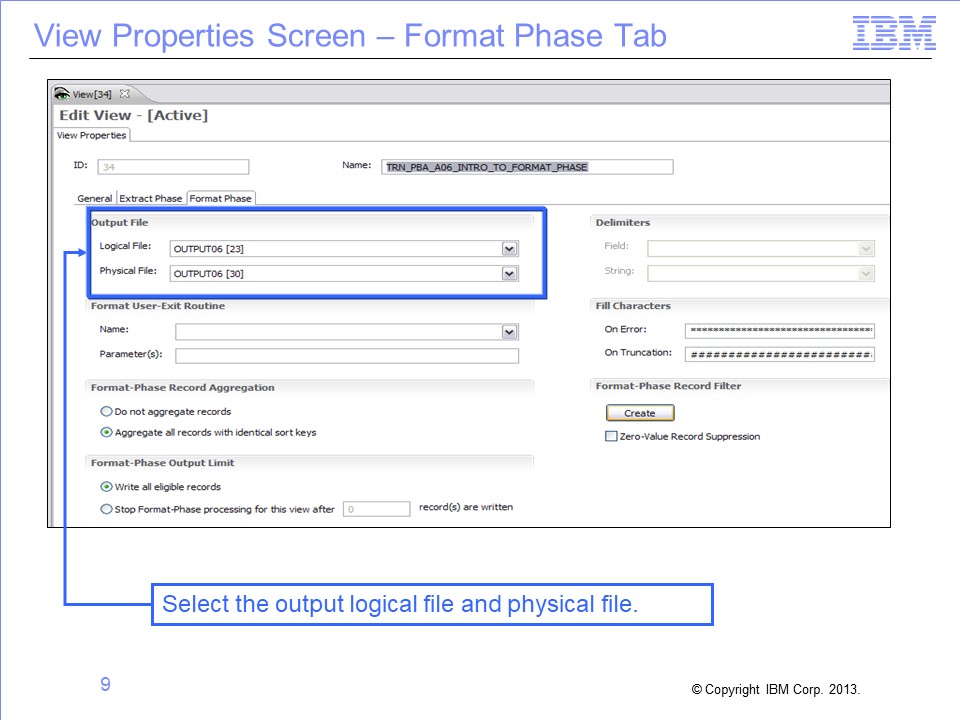
The final output file is designated by selecting the output logical and physical file on the View Properties screen. The additional steps needed to find the actual DD name that should be placed in the Performance Engine job stream are explained next.
Slide 10
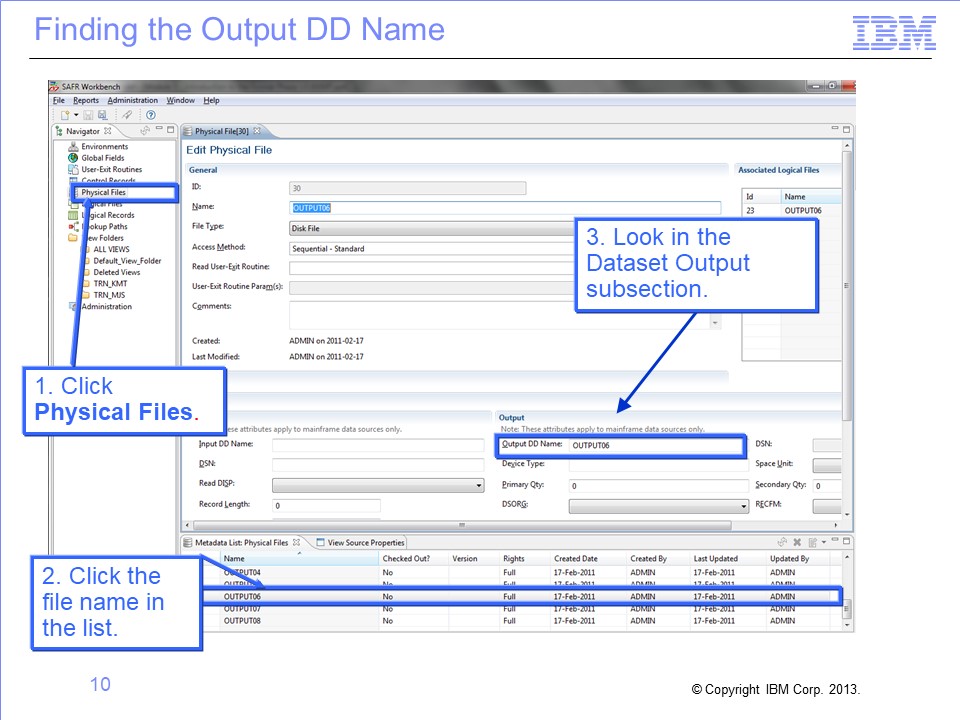
To find the output DD name associated with this physical file, follow these steps:
- Click Physical File in the navigation pane. The list of all physical files is displayed.
- Find file name in the list of physical files (ID 30 in our example) and double-click the name. The Edit Physical File page opens.
- Look in the Output subsection of the Dataset section of the page.
The output DD name in this case is OUTPUT06, which happens to be the same as the physical file name. This is a good practice in defining physical file names, but it isn’t required.
Slide 11
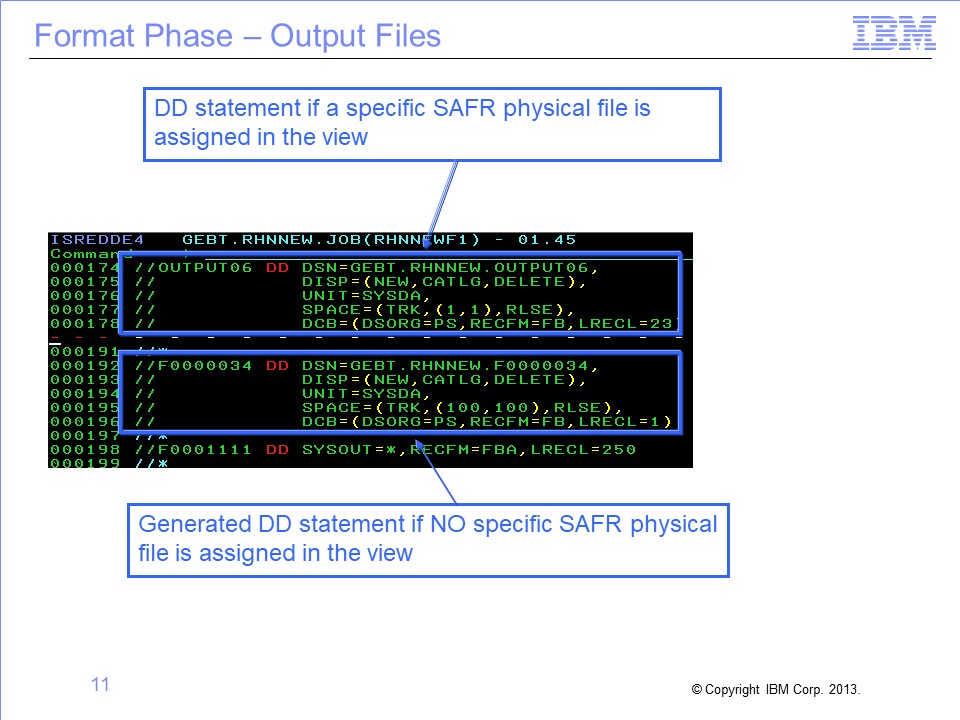
The DD statement for the output file must be placed in the JCL for the Format phase step that is running GVBMR88. Because a physical file was assigned to the view, the DD name associated with that physical file is used. In this example, the output DD name is OUTPUT06.
Note: If the physical file is not assigned, a default DD name is generated at runtime. This name is the letter “F” followed by the last seven digits of the view number, using leading zeros if required. For example, when running view 34, the DD name would be F0000034.
Slide 12
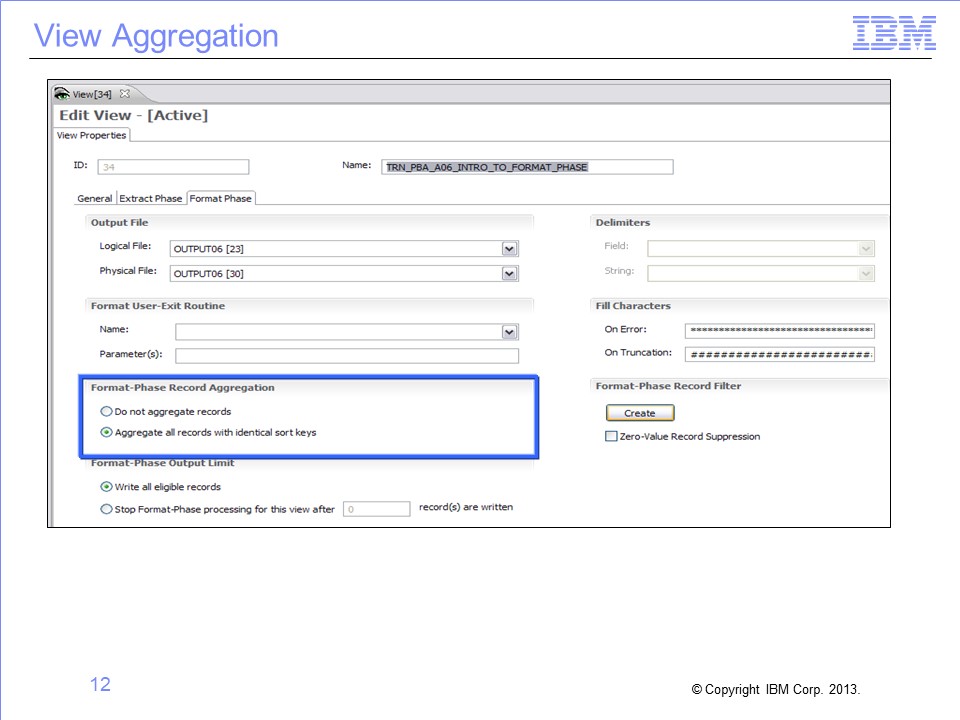
Select the option to aggregate or not aggregate work file records. Aggregation, or summarization, means subtotaling for a particular key. An example of aggregation includes subtotaling all orders for a particular customer at a particular store. The Performance Engine aggregated or summarized output includes one record for each customer at each store. Non-aggregated output lists each individual order by each customer at each store. Aggregation is similar to using a SORT=SUM statement in a sort utility.
The Format phase is required for all aggregation. Regardless of whether views are aggregated, the Format phase always results in a sorted final output file.
Slide 13
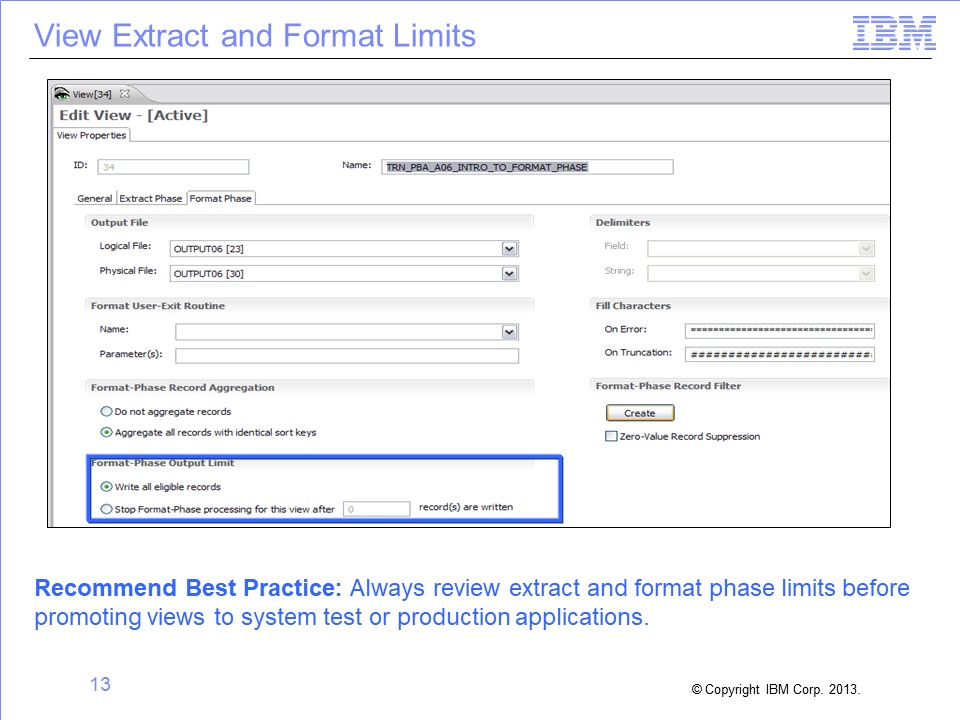
Record limits are often used during debugging to halt processing after a specified number of records are written. Although they are used in testing, these limits often are not appropriate for production applications. It is best to review the need for Extract phase limits and Format phase limits at the end of development.
Slide 14

The Format phase is also required if delimited file output is desired. Use the options in the upper right portion of the screen to select the types of delimiters needed for both strings and fields.
To specify Format phase Record Filtering, click the Create button. This allows you to specify the characteristics of records to be written or discarded after aggregation. Record filtering will be explained in another course module.
Selecting the Zero-Value Record Suppression check box is a simple way of creating a Format phase record filter that will omit all rows on which all aggregated and calculated amounts are zeros.
Slide 15

As noted, the Format phase always sorts the Extract Work file and resulting output files. Column sort keys determine how the files are sorted. Sort keys are shown in the view in yellow. The numbers within the yellow cell indicate which column will be sorted first, second, third, and so on. The arrows within the yellow box indicate whether the column is sorted in ascending or descending order. In this example, stores will be sorted first, customers second, and both will be in ascending order, for example, from 0 to 9.
Slide 16

Right-click, anywhere on the column, to open a list. Left-click to select the Make sort key option to assign that column as a sort key.
To remove a sort key from a column, follow the same process, but select the Make non-sort key option.
Slide 17

After you assign a sort key to a column, you can click in the yellow cell to display the sort key properties.
Slide 18

You change sort attributes using the fields on the Sort Key Properties tab, including the sort order, or the key number.
Changing the sort key number on the store ID from 1 to 2 means that the output file will be sorted first by customer, and then by store. Note that column placement does not affect the sort key order. Although it may be less intuitive, it is possible to sort first on customer and then by store, even though Store is the first column in the output file.
Slide 19

The order in which the file will be sorted can also be displayed by double-clicking in the Sort Keys cell. The expanded rows show which field will be sorted first and which will be sorted second.
Slide 20

Aggregation views typically have one or more alphanumeric sort columns, followed by one or more columns of amounts or counts, which are typically subtotaled. To specify the type of subtotaling, double-click in the Record Aggregation Function cell and select the function from the drop-down list.
Note that columns that are not sorted or subtotaled are permissible in Format phase views. However, when multiple records are collapsed into a single output record by the sort keys, only one of the underlying detail values is retained in the final output.
Slide 21

You can change how numbers are displayed. For example, you might want a masked value, with commas marking thousands and a period for decimals points, on a printed report. To select a mask, double-click in the Data Type cell, and then select Masked Numeric from the drop-down list.
Make sure that the column is wide enough to accommodate the size of the ultimate subtotal value. For example, the addition of two records with 3-digit numbers will require a 4-digit column. The overflow and error fill values on the View Properties Format Phase tab will be used if the column or mask size is too small.
Slide 22

The Format phase engine GVBMR88 requires a pair of files that are produced in the Extract phase; the EXT and the SXT files. The EXT file contains the actual extracted data, in the special SAFR internal format. The SXT file contains sort statements on how to sort the outputs. GVBMR88 uses a sort utility before performing the aggregation and format functions.
Slide 23

You assign an Extract Work file number on the View Properties tab. Multiple views can share an Extract Work file.
Extract Work files for the Format phase views:
- Are written in the internal SAFR Format phase format.
- Receive a header record for each view written to that Extract Work file containing a count of the records extract for that specific view, and
- Receive a control record containing a count of the total records written to that Extract Work file.
These additional records are visible on the Extract Phase Control report. Note that only 12 records were read by MR95 from the order file, but 13 records were written for view 34 to the file EXTR001: 12 input plus 1 header record. The total records written to EXTR001 are 14: the 12 input, 1 header, and 1 control record.
Slide 24

The MR88 control report shows the total records that were read from the Extract Work file (14), and the resulting aggregated or summarized records written out to all the data files (04). It also shows a breakdown of the records written for each view to their individual data files, which is also 4.
Slide 25

This module provided an overview of the Format phase. Now that you have completed this module, you should be able to:
- Describe the Format phase
- Determine when the Format phase should be employed
- Specify the view and JCL parameters necessary to use the Format phase
- Interpret the results of Format phase processing
Slide 26

Additional information about SAFR is available at the web addresses shown here.
Slide 27

Slide 28

This concludes the Module 5. Thank you for your participation.

