
The following slides are used in this on-line video :
Slide 1

Welcome to the training course on IBM Scalable Architecture for Financial Reporting, or SAFR. This is module 3: “I/O Processing and Data Types.”
Slide 2

This module provides you with an overview of I/O processing and data types. Upon completion of this module, you should be able to:
- Describe a logical record, and demonstrate its use
- Describe the attributes of a view column definition
- Name the various data formats that SAFR can read and write, and
- Locate the input and output DD names in the metadata, and update the Extract phase JCL to include these names
Slide 3

To briefly review SAFR components, the Performance Engine reads source data using definitions in the SAFR Metadata Repository, and produces outputs. Logical records describe the inputs to the Performance Engine. The view definitions define the outputs, using the columns to specify the fields. Most outputs from SAFR are data files; however, SAFR is able to produce printable reports as well.
Slide 4

A logical record is similar to a COBOL copybook. It describes the input record structure, defining each field, the data it contains, and the format of that data. The Performance Engine reads input logical records, extracting data from fields to produce various outputs. It can transform the format of input fields depending upon the outputs required.
Slide 5

The value placed in the output field is defined by the column source properties. Output formats are defined by the column properties.
In this example, the constant with the value of 1234567890 will be written as a 10-byte zoned decimal field in position 11 of the file.
Zoned decimal format will be described later in this module.
Slide 6

The start position is calculated, and indicates where that field will be placed in the output file. It is dependent upon the length of prior columns. The data type, date/time format, decimal places, and visible and signed indicators are primarily important in views that produce files.
Slide 7

The highlighted attributes are primarily important for views that produce hardcopy reports. The column headings are actually printed on hard copy reports. In views that produce files, the headings are often used to document notes about the column. The other parameters will be detailed more in a later module.
Slide 8

The Performance Engine transforms data into numerous different types, many of which are not available as standard formats in COBOL or other languages. The choice of this attribute affects other column attributes, such as length, sign, decimal place, and mask, and thus is very important in building file output views. The following slides will help you understand how values are stored.
Slide 9

To understand these data types, we’ll use hexadecimal display or “hex” for short, to highlight differences between each data type. The example here is the zoned decimal formatted number 1234567890. In most mainframe editors, hex can be displayed by using the command hex or set hex while viewing file contents. The first line shows the display value. Below each character, two digits, one on top of the other, show the hexadecimal values. Note that a number can be stored in just one hexadecimal position.
Slide 10

The Signed check box determines whether a sign is stored with the number. In the example hex display for a zone decimal field type, an F means no sign is stored, a C means the number is positive, and a D means it is negative. The location of this sign, and in some cases, the actual value for positive and negative, is dependent on the data type.
All the data types discussed on the following slides can be defined as either input (in the logical record) or as output (in the view).
Slide 11

The tables here and on the following slides show the output value for different data types. Alphanumeric is a general format, but it cannot be used to maintain the sign of numbers. It is the same as a PIC X variable type in COBOL. It is the only format applicable for text data. The contents can be read in data files, but at the cost of wasted storage for numbers.
Slide 12

Zoned decimal is a general format for storing numbers with a sign indicator. It is the same as a PIC 9 or PIC S9 variable in COBOL. If the Signed checkbox is selected, a sign is stored in the top last hex position of the number, which makes the display version of the number unreadable. In this example, the sign is an opening brace. So, although the data is generally readable, it still requires more storage for numbers than other formats require.
Slide 13

The packed data type stores the number in a more compressed form and is commonly used in many languages, such as COBOL, where it is a COMP 3 variable. Because it is compressed, numbers can only be read in hex mode, each digit taking one hex position. The last hex position is reserved for the sign, regardless of whether the Signed checkbox is selected. Selecting the Signed checkbox determines whether “C” for positive or “D” for negative is placed in the position for the sign.
Slide 14
Binary is also a common compressed format, defined in COBOL as a COMP variable. Because binary format is compressed, the Signed checkbox has no impact on positive numbers.
Binary format is even more compressed than packed, and cannot be read without a conversion tool, such as a scientific calculator with hex mode.
Slide 15
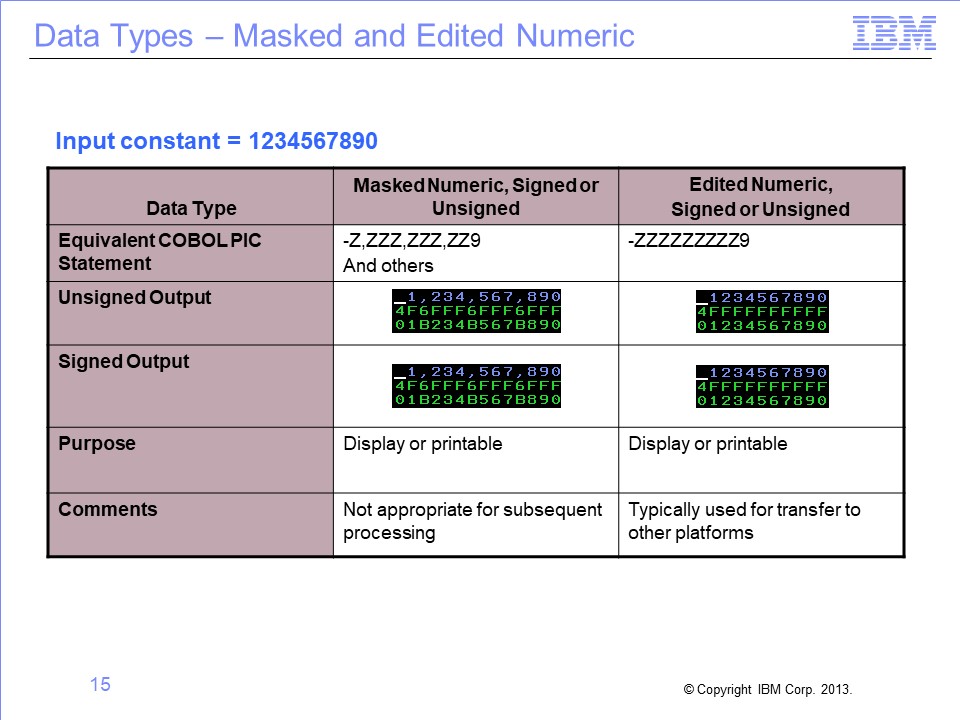
SAFR provides two other masked formats, masked numeric and edited numeric. Both are similar to a masked, printable COBOL variable. The sign becomes a dash, which is not appropriate for subsequent processing on the mainframe.
After selecting the masked numeric data type in a column, you can can also select the specific mask to apply.
In the edited numeric format, a fixed mask is used, with no commas or leading spaces. This format is often used when preparing files for transfer to another platform for continued processing.
Slide 16
Users can define three other data types: binary coded decimal, sortable packed, and sortable binary. None of these data types have a COBOL equivalent.
Despite its name, binary coded decimal is not binary. It is more like packed, without a reserved place for the sign. It is often used to store dates and times.
Sortable packed and sortable binary can be sorted from large negative numbers, descending to zero, and continue to large positive numbers. Negative numbers in both these formats are difficult to decipher without a technical aid.
Slide 17
Masks override any value in the decimal field, regardless of whether the Signed checkbox is selected. In this example, the parentheses on the mask are used for negative numbers, and the output is signed even though the Signed checkbox is not selected. The mask has two decimal places, not the one decimal place defined in the Decimal Places field.
The Performance Engine aligns the decimal points from the input with the output and truncates or zero-pads if necessary. In this example, the input constant has three digits after the decimal place, but the mask has only two. The last digit is truncated in the output, and the negative constant is reflected in the parentheses.
Slide 18
Zoned decimal, packed, binary, and binary coded decimal all have implicit decimals. The output will have no explicit decimal point. However, again the Performance Engine aligns decimal points from input to output and fills with zeros if necessary.
In this example, the constant has three decimal points, but the output column specifies only one. Thus the final two digits, the 9 and 0, are truncated in the output.
Slide 19
In this example, we have replaced the constant input with a source field input. When the value of this field is moved from the input to the output, it will be transformed. It will be read as a 6-byte packed field and written as a 14-byte zone decimal. It will also have two decimal points added to it.
Note that you convert from one data type to another, the column widths may have to change. In this example, if the input 6-byte packed field were placed in a 6-byte zoned decimal output field, five digits would be truncated. On the other hand, if an input zoned decimal field is placed in a packed output field of the same size, space will be wasted.
Slide 20
This table shows the field limits for the different fields, and the number of decimals allowed in each field format. Each decimal place counts as a space in the maximum value of the number. For example, a packed field can be up to 31 digits in length, composed of 30 digits to the left and 1 digit to the right of the decimal point, or 22 digits to the left and 9 decimal places.
Note that, for the edited and masked numeric formats, the field length may be 256 bytes, but the practical limit is 31 digits for any data involved in a calculation, subtotal, data type transformation, or masking.
Slide 21
The Date/Time Format field further describes how dates and times are stored within the field. This enables certain date functions within SAFR.
In this example, we’ve added a date column to the prior view. The source contains the date in CCYYMMDD format, but the column output specifies a DD/MM/CCYY format. The Performance Engine moves the day from the last position to the first.
Note that, because the output requires slashes in the date, the column is a 10-byte field, not the 8 bytes on input.
Slide 22

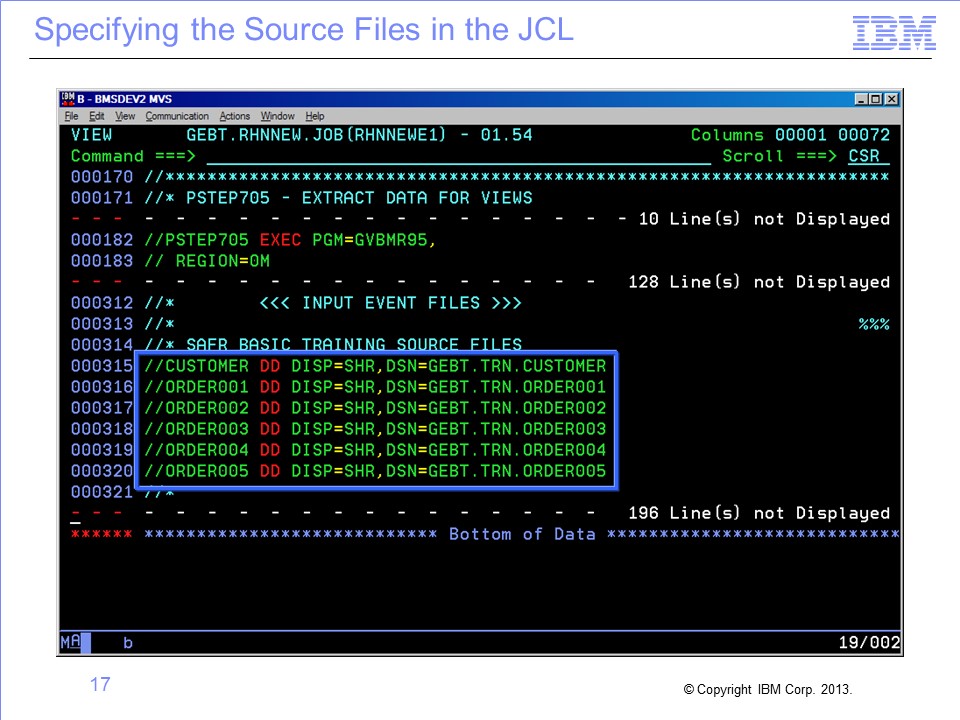
DD names connect logical records and views to actual physical files read by the Performance Engine.
To find the DD name associated with an LR, we must first locate its associated logical file. The logical record for the view is shown in the View Source cell. Open the view in the Workbench and click in the blue View Source cell. The View Source Properties frame opens and displays the logical file, which in this case is ORDER_001.
Slide 23

To display logical and physical files, follow these steps:
Step 1: To see a list of all logical files, click the Logical File icon in the Navigator pane. The Logical File list opens.
Step 2: Scroll down the list until you find the ORDER_001 logical file, and then double-click the file name. The Logical File Editor opens.
Step 3: Find the physical file associated with this logical file by looking in the Associated Physical Files section of the page. The physical file here is named ORDER_001, which just happens to be the same as the name of the logical file.
Slide 24
To display the physical file and Input DD name, follow these steps:
Step 1: Click on the Physical File icon in the Navigator pane. A list of all physical files is displayed.
Step 2: Scroll down the list until you find the ORDER_001 physical file, and then double-click the file name. The physical file is displayed.
Step 3: To find the input DD name associated with this physical file, look in the Dataset section of the frame, and then the Input subsection. The input DD name in this case is ORDER001.
Slide 25

Now that you know that your view retrieves data from the DD name ORDER001, make sure that a DD statement for ORDER001 is included in your JCL and is referencing the appropriate data set.
Next let’s find the DD name for the output file.
Slide 26
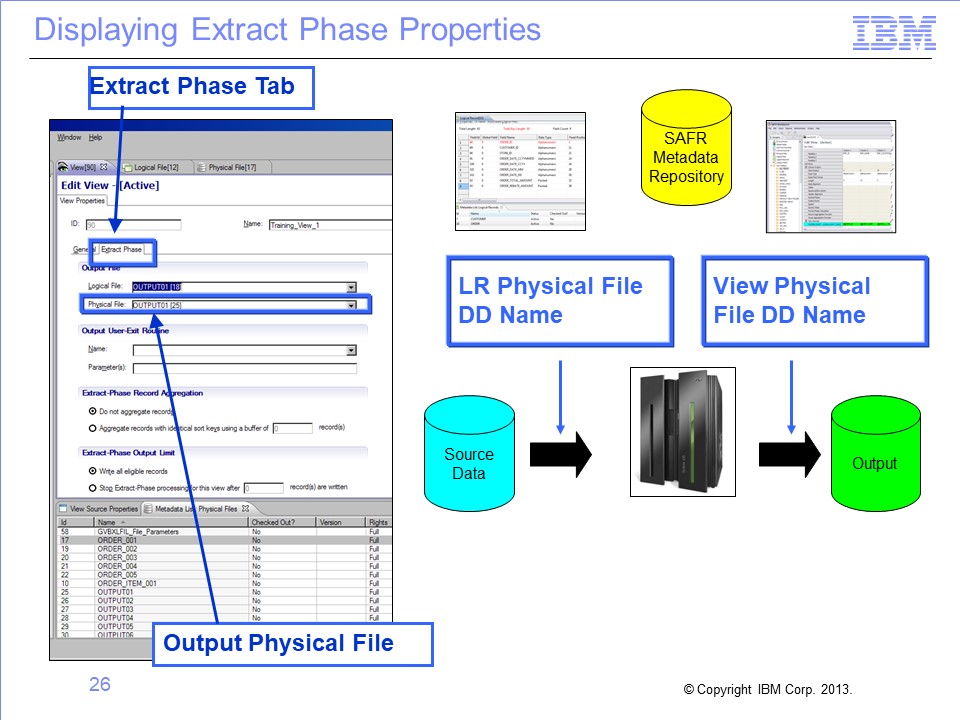
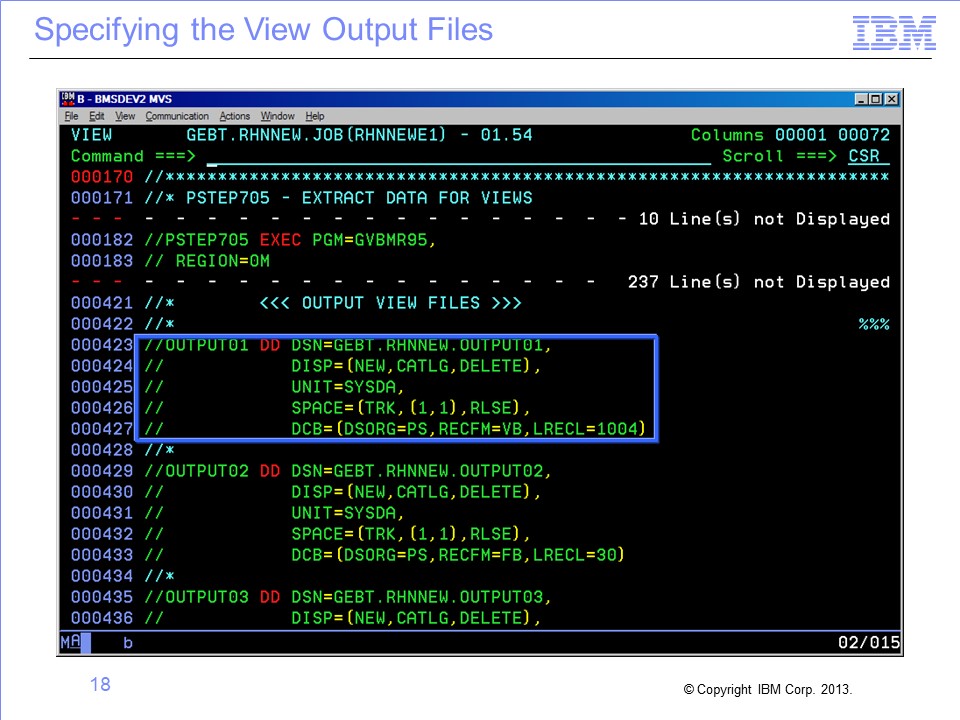
View output is written to the physical file listed in the view properties. If the view does not require the Format phase, find the output DD name to place in the JCL by opening the view in the Workbench, navigating to the View Properties tab and clicking the Extract Phase tab.
Next, find the physical file in the Output File section of the tab. If the physical file value is blank, a new DD name will be generated at runtime. This name will consist of the letter “F” followed by the last seven digits of the view number, using leading zeros if required. If the physical file value is not blank, you must find the output DD name associated with the physical file. In this example, the output physical file is OUTPUT01.
Slide 27
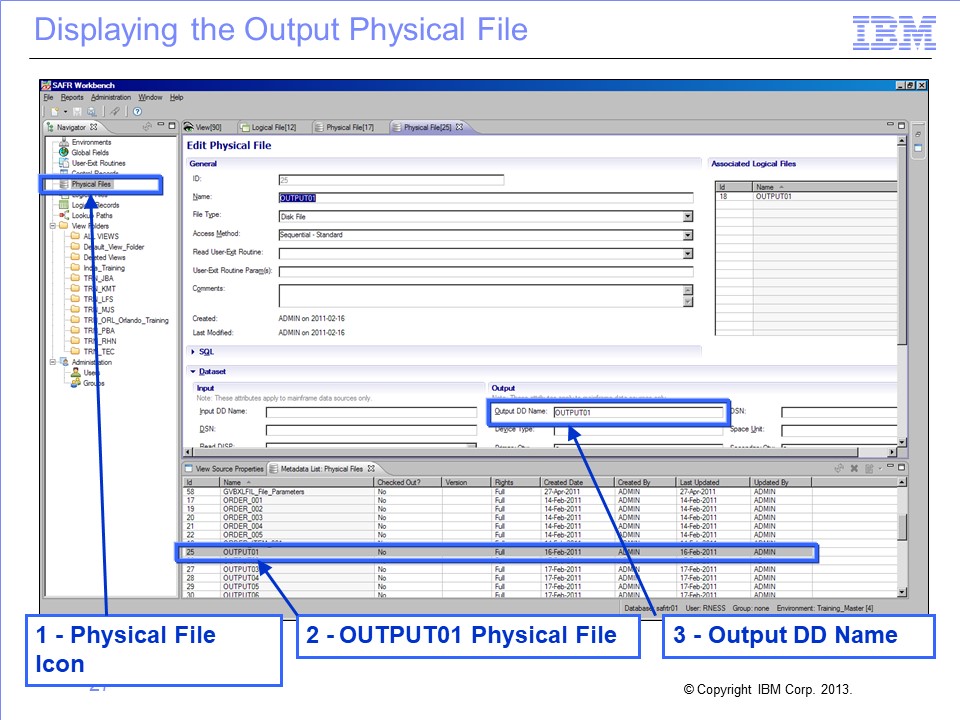
Find the DD name for physical file OUTPUT01 by selecting Physical Files from the Navigator pane and then scrolling down in the Physical File list until you find the OUTPUT01 physical file. Double-click the file name.
The Physical File Editor frame for OUTPUT01 opens.
Find the output DD name associated with this physical file by looking in the Dataset section of the frame and then looking in the Output subsection. The output DD name in this case is OUTPUT01, which happens to be the same as the physical file name, but this isn’t always the case.
Slide 28
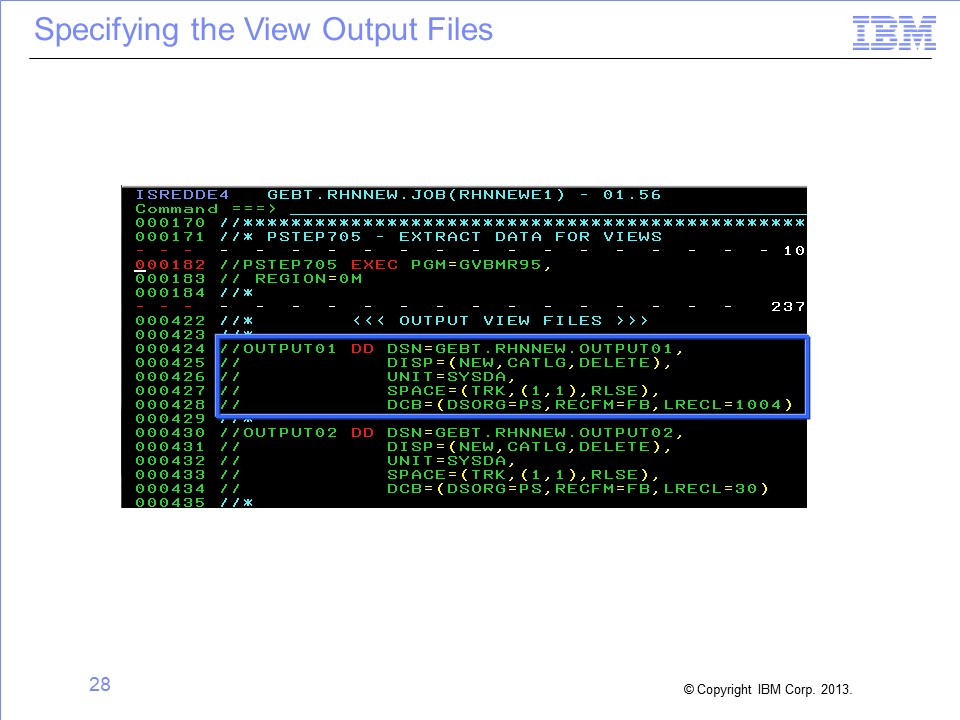
Now that you know that your view writes data to the DD name OUTPUT01, make sure that a DD statement for OUTPUT01 is included in your JCL and is referencing the appropriate data set.
Slide 29

This module provided an overview of I/O processing and data types. Now that you have completed this module, you should be able to:
- Describe a logical record, and demonstrate its use
- Describe the attributes of a view column definition
- Name the various data formats that SAFR can read and write
- Locate the input and output DD names in the metadata, and update the Extract phase JCL to include these names
Slide 30

Slide 31

This concludes the Module 3. Thank you for your participation.

